Abstract
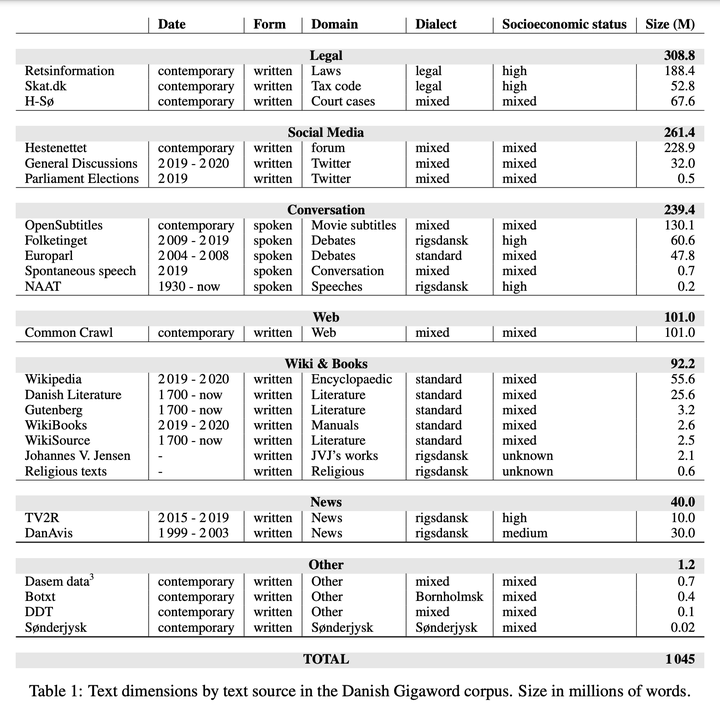
Danish language technology has been hindered by a lack of broad-coverage corpora at the scale modern NLP prefers. This paper describes the Danish Gigaword Corpus, the result of a focused effort to provide a diverse and freely-available one billion word corpus of Danish text. The Danish Gigaword corpus covers a wide array of time periods, domains, speakers’ socio-economic status, and Danish dialects.
Type
Publication
Proceedings of NODALIDA
Leon Derczynski
Associate professor
My research interests include NLP for misinformation detection and verification, clinical record processing, online harms, and efficient AI.
Manuel R. Ciosici
USC/ISI
Manuel researches in temporal semantics, story structure, and information-theoretic methods.