PROCAT: Product Catalogue Dataset for Implicit Clustering, Permutation Learning and Structure Prediction
Abstract
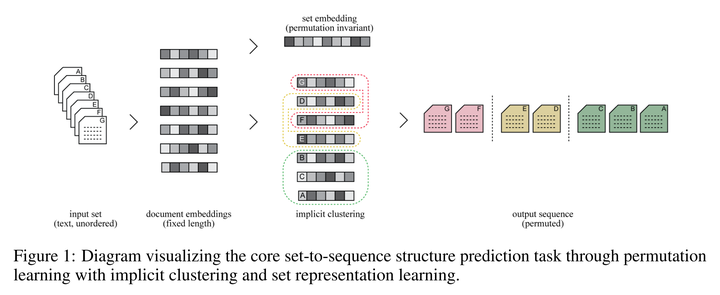
In this dataset paper we introduce PROCAT, a novel e-commerce dataset containing expertly designed product catalogues consisting of individual product offers grouped into complementary sections. We aim to address the scarcity of existing datasets in the area of set-to-sequence machine learning tasks, which involve complex structure prediction. The task’s difficulty is further compounded by the need to place into sequences rare and previously-unseen instances, as well as by variable sequence lengths and substructures, in the form of diversely-structured catalogues. PROCAT provides catalogue data consisting of over 1.5 million set items across a 4-year period, in both raw text form and with pre-processed features containing information about relative visual placement. In addition to this ready-to-use dataset, we include baseline experimental results on a proposed benchmark task from a number of joint set encoding and permutation learning model architectures.
Mateusz Jurewicz
PhD fellow
Mateusz researches in neural set-to-sequence models and catalogue/sequence optimisation.
Leon Derczynski
Associate professor
My research interests include NLP for misinformation detection and verification, clinical record processing, online harms, and efficient AI.